DeFi断崖式波动下的基石 HDFS分布式存储如何构建大数据安全与处理新范式
去中心化金融(DeFi)领域再次经历“断崖式”行情,剧烈的价格波动不仅考验着投资者的神经,更以海量、高频、高价值的交易数据洪流,向底层数据处理与存储系统发出了严峻挑战。在这一背景下,稳定、可靠、安全的数据基础设施成为支撑DeFi乃至整个数字经济发展的生命线。以Hadoop分布式文件系统(HDFS)为代表的分布式存储技术,正以其独特的架构优势,为大数据的安全处理与存储提供着坚实、可扩展的支持服务,成为动荡市场中的“定海神针”。
一、DeFi数据洪流:挑战与需求
DeFi应用7x24小时不间断运行,每一笔交易、每一次流动性池变化、每一个预言机报价都生成海量结构化与非结构化数据。市场剧烈波动期间,数据产生速率呈指数级增长,呈现出典型的“大数据”特征:
- 体量巨大(Volume):链上交易、合约交互、价格信息等数据持续累积,已达PB甚至EB级。
- 产生高速(Velocity):秒级甚至毫秒级的数据更新,要求极低延迟的写入与读取能力。
- 类型多样(Variety):包括交易日志、智能合约代码、用户地址、市场情绪文本、多维图表等。
- 价值密度与安全要求极高(Value & Veracity):数据直接关联巨额资产,必须确保绝对的真实性、完整性、不可篡改性与隐私性。
传统中心化存储方案在可扩展性、成本、单点故障风险方面已难以应对。此时,分布式存储的必要性凸显。
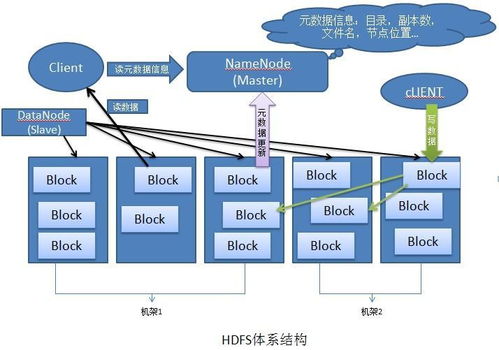
二、HDFS:构建分布式存储的坚实底座
HDFS作为大数据生态的基石,其核心设计理念完美契合了上述需求:
- 高容错与高可靠:采用多副本机制(默认3副本),将数据块分布在不同服务器上。即使某个节点(类比DeFi中某个验证者节点失效)发生故障,数据也不会丢失,服务不会中断,为关键金融数据提供了“冗余安全”。
- 高吞吐量数据访问:优化了流式数据读取,适合DeFi场景下大量的顺序数据写入与分析查询(如历史交易分析、风险监控),而非低延迟的随机访问。
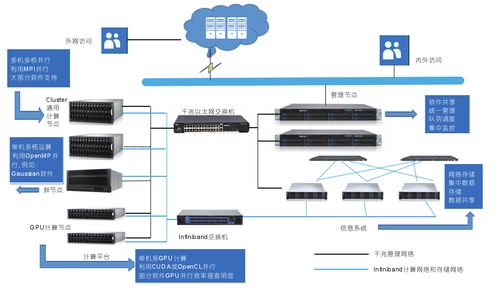
- 大规模数据集与线性扩展:能够轻松部署在成百上千台廉价商用服务器集群上,通过横向扩展存储与计算能力,从容应对数据量的爆炸式增长。存储空间和计算力“按需扩展”,经济高效。
- 一次写入,多次读取模型:非常适合DeFi中一旦上链即不可篡改(追加性质)的数据存储范式,为审计、监管、事后分析提供了稳定可靠的数据源。
三、赋能大数据安全与处理:HDFS的核心支持服务
在DeFi大数据处理流水线中,HDFS扮演着核心存储层的角色,支持上层各类处理框架(如Spark、Flink、Hive),共同提供以下关键服务:
- 安全的数据湖仓库:HDFS可以作为原始、清洗后、加工后的各级DeFi数据的集中存储池(数据湖)。通过严格的权限控制(Kerberos认证、ACL)、数据加密(静态加密)和审计日志,确保敏感数据(如匿名化后的交易关联图)在存储层面的安全。
- 高通量数据处理的基础:风险监测模型、量化交易策略、流动性分析等都需要对海量历史数据进行批量计算或流式计算。HDFS提供的高带宽和并行I/O能力,使得Spark等计算引擎能够高效地并行读取数据,完成复杂的风险价值(VaR)计算、异常交易模式识别等任务。
- 容灾与备份的基石:通过跨机房、跨地域的HDFS联邦(Federation)或镜像部署,可以实现数据的异地容灾。这对于要求极端可用性的DeFi协议和托管服务商至关重要,确保在任何局部故障或灾难下,核心数据不丢,业务可快速恢复。
- 支持链上链下数据融合分析:DeFi分析不仅需要链上数据,还需结合链下市场数据、社交媒体舆情、传统金融信息等。HDFS能够统一存储这些多源异构数据,为构建全面的市场视图和风险评估模型提供支持。
四、面向未来的演进:与区块链存储的协同
值得注意的是,HDFS与新兴的区块链分布式存储(如Filecoin, Arweave)并非替代关系,而是互补协同。HDFS更侧重于高性能、高吞吐的热数据存储与处理,服务于实时性要求高的分析和应用;而区块链存储更擅长于提供不可篡改、可验证的冷数据归档和长期存证。未来架构可能是:热数据在HDFS集群中进行高速处理分析,处理后的关键结果或需要永久存证的原始数据哈希值锚定到区块链上,形成分层、高效、可信的数据管理体系。
###
DeFi世界的波动无常,愈发凸显底层数据基础设施稳定性的价值。HDFS以其久经考验的分布式架构,为处理DeFi孕育的“数据洪流”提供了可扩展、高可靠、高吞吐的存储解决方案。它不仅是大数据分析和AI模型训练的基石,更是保障数据资产安全、支持业务连续性的关键。随着DeFi与实体经济融合加深,数据量维度的进一步攀升,以HDFS为代表的成熟分布式存储技术,将继续作为不可或缺的支持服务,为构建一个更稳健、更透明、更具洞察力的数字金融未来保驾护航。
如若转载,请注明出处:http://www.yuanwangyun.com/product/63.html
更新时间:2026-06-19 18:12:14